지난 번 포스팅에는 LBPH 알고리즘으로 얼굴 인식을 태스크를 진행했다. 이번에는 68개의 얼굴 포인트를 감지해서 정확도를 높혀보고자 한다.
1. 라이브러리 가져오기
import dlib
import cv2
import PIL import Image
from google.colab.patches import cv2_imshow
2. 데이터셋 가져오기
import os
import zipfile
path = "~/yalefaces.zip"
zip_object = zipfile.ZipFile(file=path, mode='r') #read
zip_object.extractall("./")
zip_object.close() # 메모리 해제
3. 태스크와 모델 정의
# dlib에서 어떤 태스크를 수행할 것이며,
face_detector = dlib.get_frontal_face_detector()
# face points 모델을 가져옴
points_detector = dlib.shape_predictor("~/shape_predictor_68_face_landmarks.dat")dlib에 있는 함수 get_frontal_face_detector로 얼굴을 탐지할 것이고 (빨간 사각형), shape_predictor로 60개의 랜드마크(초록색 원)을 구축해볼 것이다.
4. 얼굴 탐지
import matplotlib.pyplot as plt
index = {}
idx = 0
paths = [os.path.join("~/train", f) for f in os.listdir("~/train")]
for path in paths:
image = Image.open(path).convert("RGB") #dlib는 Gray scale로 굳이 바꾸지 않아도 됨
image_np = np.array(image, "uint8")
face_detection = face_detector(image_np, 1)
for face in face_detection:
l, t, r, b = face.left(), face.top(), face.right(), face.bottom()
cv2.rectangle(image_np, (l,t), (r,b), (0, 0, 255), 2)
cv2.imshow(image_np)
이번에는 68개의 랜드마크를 추가해서 눈썹, 눈, 코, 얼굴형, 입의 위치 정보를 가져와보자.
import matplotlib.pyplot as plt
index = {}
idx = 0
face_descriptors = None
paths = [os.path.join('/content/yalefaces/train', f) for f in os.listdir("/content/yalefaces/train")]
for path in paths[:4]:
print(path)
image = Image.open(path).convert("RGB") #open cv 때는 L로 바꿨어야 했음 # dlib는 안해도됨.
image_np = np.array(image, 'uint8')
face_detection = face_detector(image_np, 1)
for face in face_detection:
l ,t, r, b = face.left(), face.top(), face.right(), face.bottom()
cv2.rectangle(image_np,(l,t), (r,b), (0, 0, 255),2 )
points = points_detector(image_np, face)
for point in points.parts():
cv2.circle(image_np, (point.x, point.y), 4, ( 0,255,0), 1)
cv2_imshow(image_np)
여기까지가 얼굴 탐지, 그리고 68개의 랜드마크를 적용한 모습이다. 이제는 이 68개의 랜드마크의 값을 신경망 모델에 투입해보자. 결과부터 말하자면, 128개의 벡터값으로 출력된다.
5. 신경망 모델 추가
import matplotlib.pyplot as plt
# 신경망 모델 추가 Resnet
# 찾은 얼굴을 넘파이 배열 형태의 벡터로 변환하기 위함
# 해당 모델은 구글링해서 쉽게 찾을 수 있음
face_descriptor_extractor = dlib.face_recognition_model_v1("~/dlib_face_recognotion_resnet_model_v1.dat")
index = {}
idx = 0
face_descriptors = None
paths = [os.path.join('/content/yalefaces/train', f) for f in os.listdir("/content/yalefaces/train")]
for path in paths:
print(path)
image = Image.open(path).convert("RGB")
image_np = np.array(image, 'uint8')
face_detection = face_detector(image_np, 1)
for face in face_detection:
l ,t, r, b = face.left(), face.top(), face.right(), face.bottom()
cv2.rectangle(image_np,(l,t), (r,b), (0, 0, 255),2 )
points = points_detector(image_np, face)
for point in points.parts():
cv2.circle(image_np, (point.x, point.y), 4, ( 0,255,0), 1)
face_descriptor = face_descriptor_extractor.compute_face_descriptor(image_np, points)
# 68개의 얼굴 포인트를 추출해서, 눈,코,입 정보 + 위치 정보를 신경망에 입력하면
# 신경망이 얼굴마다 128개의 값을 return한다는 것만 알면 됨. 출력값은 이해하기 어려움
face_descriptor = [f for f in face_descriptor] # 얼굴 하나에 대한 정보가 담김
face_descriptor = np.asarray(face_descriptor, dtype=np.float64) #shape -> [128,]
face_descriptor = face_descriptor[np.newaxis, :] #내부에 하나의 차원을 더 추가 [1, 128]
if face_descriptors is None:
face_descriptors = face_descriptor
else:
face_descriptors = np.concatenate((face_descriptors, face_descriptor), axis=0) # 얼굴 하나마다 열 하나 추가
index[idx] = path
idx += 1face_descriptors.shape(132, 128)이 모델을 통해 나온 결과는 132개의 이미지가 있고, 각각은 128개의 벡터로 출력되었다.
face_dscriptorsarray([[-0.20066287, 0.1722272 , 0.0231601 , ..., -0.04161052,
0.07079843, 0.06662951],
[-0.1343661 , 0.11907996, 0.08364151, ..., -0.00033966,
0.09805366, 0.06048028],
[-0.15895709, 0.17177498, 0.08591322, ..., 0.01587936,
0.06433959, 0.04638684],
...,
[-0.16209717, 0.07414564, 0.04381339, ..., -0.00272495,
0.11123617, 0.01131051],
[-0.09726074, 0.17717779, 0.03324226, ..., -0.10175261,
0.05613339, 0.0554654 ],
[-0.1603734 , 0.04354453, -0.00962381, ..., -0.01995603,
0.03070256, 0.05987303]])
정리해보자면, 68개의 랜드마크(초록색 원)를 신경망 모델에 입력으로 넣고 내부적으로 계산한 후 128개의 벡터로 출력하고, 이 벡터들은 개인의 얼굴에서 가장 중요한 특징을 포함한다. resnet은 블랙박스 모형이라 내부적으로 어떻게 연산되었는지는 모른다.
좋다. 개인별로, 132장에서 128개의 벡터를 추출했는데 어떻게 얼굴을 분류할 것인가? 얼굴 간에 거리를 재서 분류한다.
얼굴 거리 재기
먼저, 마지막 사람의 벡터값을 보자.
face_descriptors[131]array([-0.1603734 , 0.04354453, -0.00962381, -0.01603908, -0.10903208,
-0.00973412, -0.00454159, -0.07255259, 0.14447317, -0.08075062,
0.11149375, -0.07765995, -0.26110888, 0.00914971, 0.002272 ,
0.11110201, -0.14372125, -0.15022841, -0.16450351, -0.10650715,
0.04024157, -0.00938175, -0.07378244, 0.02648143, -0.14911367,
-0.31542563, -0.05809046, -0.07712189, 0.04348422, -0.09141375,
-0.09675201, 0.04188032, -0.24156773, -0.11758132, 0.03321011,
-0.0089935 , -0.00607019, -0.0257321 , 0.17242202, 0.03391106,
-0.15322645, 0.01330262, 0.08265863, 0.28063744, 0.13726813,
0.14198081, -0.03027285, -0.05383754, 0.13309653, -0.30064622,
0.11360931, 0.15556002, 0.08535967, 0.02296959, 0.0835216 ,
-0.15379502, -0.0261395 , 0.03199915, -0.2162599 , 0.15868129,
0.15155795, -0.05859222, -0.13945694, -0.1398325 , 0.20793964,
0.16422656, -0.09818362, -0.12197748, 0.18633005, -0.14587873,
-0.00588247, -0.02596878, -0.06149183, -0.17054772, -0.25274515,
0.05619001, 0.4330346 , 0.15112902, -0.16028538, 0.00201325,
-0.06493969, -0.05226127, 0.11247802, 0.02292845, -0.09977198,
-0.01820401, -0.01314569, 0.0986236 , 0.22318494, 0.02981644,
-0.0107182 , 0.21229219, 0.01285524, -0.05435671, 0.0155553 ,
0.05013657, -0.13023151, -0.06850564, -0.12630944, 0.01401188,
0.09994766, -0.0869334 , 0.03495812, 0.13067389, -0.1271726 ,
0.1176844 , -0.02597581, -0.0105283 , -0.00761209, 0.01793402,
-0.15820108, -0.05695678, 0.08880061, -0.21437852, 0.16955607,
0.13061601, 0.0181677 , 0.0693244 , 0.01878992, 0.04687583,
0.06487526, 0.06135333, -0.20980205, -0.14290193, 0.09487779,
-0.01995603, 0.03070256, 0.05987303])
이 사람의 벡터값이 출력되었다. 같은 이미지(사람)라면 벡터값을 뺐을 때 0이 나와야한다. 차이가 없으니까.
np.linalg.norm(face_descriptors[131] - face_descriptors[131])0.0
실제로, 같은 이미지(사람)라서 벡터값을 뺏을 때 0이 나왔다. np.linalg.norm 는 벡터간 거리를 잴 때 사용한다. norm은 노름의 norm이다. 이미지(사람) 간의 얼굴 거리 예를 몇 가지 가져왔다.
# 다른 사람
np.linalg.norm(face_descriptors[131] - face_descriptors[130])0.5188016682837002# 사람 A의 놀란 표정 vs 사람 A의 행복한 표정
np.linalg.norm(face_descriptors[131] - face_descriptors[128])0.31155000858437343
# 안경 쓰지 않은 사람 B vs 안경 쓰지 않은 사람 C
np.linalg.norm(face_descriptors[125] - face_descriptors[129])0.677754510159631
0에 가까울수록 같은 사람, 1에 가까울수록 다른 사람이다.
Q. 131번의 사람과 얼굴 거리가 적은 사람은?
np.linalg.norm(face_descriptors[131] - face_descriptors, axis=1)
# 차이가 적은 얼굴은?
np.argmin(np.linalg.norm(face_descriptors[131] - face_descriptors, axis=1))131완전히 같은 이미지라면 차이값이 0이니까 같은 번호로 출력되었다.
Q. 그럼, 똑같은 이미지를 제외하고 얼굴 거리가 적은 사람은?
# 차이가 적은 얼굴은?
# 0인 사람 - 0을 제외한 이미지
np.argmin(np.linalg.norm(face_descriptors[0] - face_descriptors[1:], axis=1))46
46이라면, 위 코드에서 만들었던 index 변수를 통해 확인할 수 있다.
index

0번인 사람은 subject01이다. subject01의 얼굴 거리가 적은 게 46으로 출력되었는데, 우리가 아까 0을 제외한 이미지로 봤으니 1씩 추가해준다. 그래서 47 인덱스가 가장 얼굴 거리가 적을 것이라 예측했다. 실제로 47번 인덱스가 subject01이다.
이제 모든 이미지에 적용을 해보자.
import os
# threshold값 이하인 경우에만 subject번호 출력
# threshold를 조정해보면서 튜닝해보자.
threshold = 0.6
predictions = []
expected_outputs = []
paths = [os.path.join("/content/yalefaces/test", f) for f in os.listdir("/content/yalefaces/test")]
for path in paths:
image = Image.open(path).convert("RGB")
image_np = np.array(image, 'uint8')
face_detection = face_detector(image_np, 1)
for face in face_detection:
points = points_detector(image_np, face)
face_descriptor = face_descriptor_extractor.compute_face_descriptor(image_np, points)
face_descriptor = [f for f in face_descriptor] # 얼굴 하나에 대한 정보가 담김
face_descriptor = np.asarray(face_descriptor, dtype=np.float64) #shape -> [128,]
face_descriptor = face_descriptor[np.newaxis, :] #내부에 하나의 차원을 더 추가 [1, 128]
# 얼굴 거리 계산
distances = np.linalg.norm(face_descriptor - face_descriptors, axis= 1)
# 얼굴 차이가 적은 인덱스
min_index = np.argmin(distances)
# 얼굴 차이값
min_distance = distances[min_index]
if min_distance <= threshold:
name_pred = int(os.path.split(index[min_index])[1].split('.')[0].replace('subject', ''))
else:
name_pred = "not identifed"
name_real =int(os.path.split(path)[1].split('.')[0].replace('subject', ''))
predictions.append(name_pred)
expected_outputs.append(name_real)
cv2.putText(image_np, "Pred: " + str(name_pred), (10, 30), cv2.FONT_HERSHEY_COMPLEX_SMALL, 1, (0, 255, 0))
cv2.putText(image_np, "EXP: " + str(name_real), (10, 50), cv2.FONT_HERSHEY_COMPLEX_SMALL, 1, (0, 255, 0))
cv2_imshow(image_np)
predictions = np.array(predictions)
expected_outputs = np.array(expected_outputs)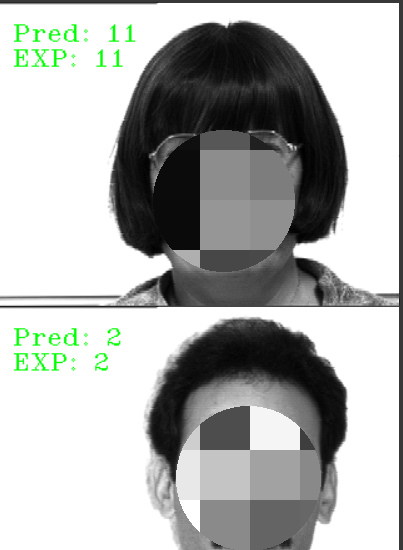
from sklearn.metrics import accuracy_score
accuracy_score(predictions, expected_outputs)0.9666666666666667
결론
LBPH 알고리즘의 디폴트 정확도는 66%였고 하이퍼파라미터 튜닝을 통해 70%까지 올렸다. 그러나, 이번 포스팅인 얼굴 간 거리값을 활용했을 때의 정확도는 약 97%다. 이를 통해 벡터값은 각 이미지에서 중요한 특징값을 가지고 있다는 것을 알 수 있다.
'DL > Computer Vision' 카테고리의 다른 글
| Computer Vision - [선형 AutoEncoder를 활용한 이미지 축소 및 복원] (1) | 2024.02.27 |
|---|---|
| Computer Vision - [CNN with tensorflow] (0) | 2024.02.20 |
| Computer Vision - [얼굴 인식 (Face Recogintion)] (1) | 2024.02.01 |
| Computer Vision - [Fruit and Vegetable Classification] (1) | 2024.01.29 |
| Computer Vision - [CNN (Convolutional Neural Network)] (1) | 2024.01.26 |