과일과 채소의 이미지를 보고 분류하고자 한다. MobileNetV2 모델을 전이 학습했다. 해당 데이터셋에는 바나나, 사과, 배, 포도, 오렌지, 옥수수, 양파, 감자, 레몬 등으로 구성되어 있다. 데이터셋은 Kaggle Dataset을 활용한다.
https://www.kaggle.com/datasets/kritikseth/fruit-and-vegetable-image-recognition
Fruits and Vegetables Image Recognition Dataset
Fruit and Vegetable Images for Object Recognition
www.kaggle.com
1. Load library
사용할 라이브러리를 가져오자.
import pandas as pd
import numpy as np
import cv2
import torch
import torchvision
import os
from pathlib import Path
import matplotlib.pyplot as plt
import tensorflow as tf
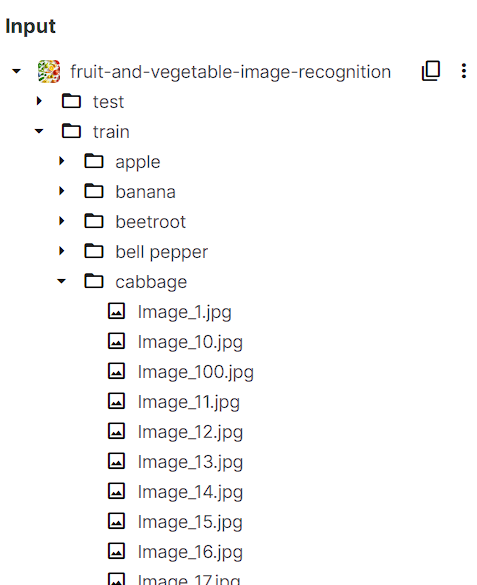
2. Load Path
학습 데이터 경로를 지정해주고, 각 폴더에 있는 jpg 확장자 파일을 가져온다. *은 와일드카드다.
train_dir = Path("/kaggle/input/fruit-and-vegetable-image-recognition/train")
train_filepaths = list(train_dir.glob(r'**/*.jpg'))
test_dir = Path("/kaggle/input/fruit-and-vegetable-image-recognition/test")
test_filepaths = list(test_dir.glob(r'**/*.jpg'))
val_dir = Path('../input/fruit-and-vegetable-image-recognition/validation')
val_filepaths = list(test_dir.glob(r'**/*.jpg'))
3. Precessing image
데이터셋의 경로를 다 가져왔으니, 각 이미지에 대해 전처리를 시작한다.
def proc_img(filepath):
# ~/apple/Image_1.jpg 로 되어 있는데, / 를 기준으로 구분하고 2번 째 인덱스인 apple을 가져온다
labels = [str(filepaths[i]).split("/")[-2] for i in range(len(filepath))]
filepath = pd.Series(filepath, name='Filepaths').astype(str)
labels = pd.Series(labels, name='Label')
df = pd.concat([filepath, labels], axis=1)
# 데이터셋 순서에 따른 편향을 없개 위해 행 전체를 섞는다.
df = df.sample(frac=1).reset_index(drop=True)
return df
train_df = proc_img(train_file_paths)
test_df = proc_img(test_file_paths)
val_df = proc_img(val_filepaths)print('-- Training set --\n')
print(f'Number of pictures: {train_df.shape[0]}\n')
print(f'Number of different labels: {len(train_df.Label.unique())}\n')
print(f'Labels: {train_df.Label.unique()}')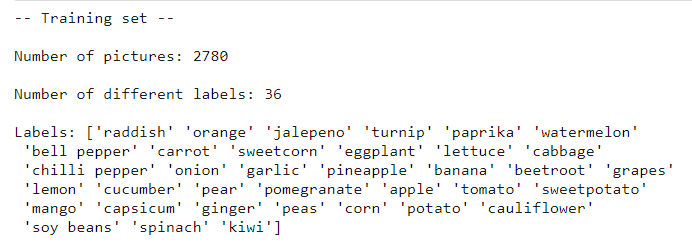
train_df.head(3)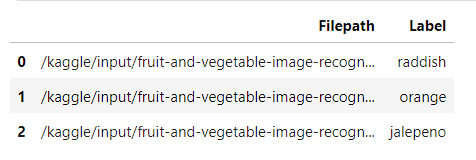
# 고유한 레이블만 추출
df_unique = train_df.copy().drop_dubplicates(subset=['Label']).reset_index()
f, axes = plt.subplots(3,6, figsize=(8,7))
for i, ax in enumerate(axes.flat):
ax.imshow(plt.imread(df_unique.Filepath[i]))
plt.tight_layout();
간단하게 데이터를 살펴봤으니, 이제 신경망 전이학습을 시작해보자.
4. Load Image, Dataset Generator and Data Augmentation
이미지를 가져오고, 이미지 데이터셋 생성 그리고 이미지 증강을 해보자. MobileNetV2 모델을 사용(전이 학습)하고, 모델에 맞게 적합한 방식으로 이미지 전처리를 실시해준다.
# 학습 데이터셋
train_generator = tf.keras.preprocessing.image.ImageDataGenetator(
preprocessing_function = tf.keras.applications.mobilenet_v2.preprocess_input
)
# 테스트 데이터셋
test_generator = tf.keras.preprocessing.image.ImageDataGenerator(
preprocessing_function = tf.keras.applications.mobilenet_v2.preprocess_input
)
위 코드에서 tf.keras.applications.mobilenet_v2.preprocess_input은 MobileNetV2 모델에 적합한 방식으로 이미지를 전처리하는 함수다. 이 함수는 이미지의 픽셀 값을 모델이 훈련될 때 사용된 범위로 조정한다.
학습 데이터, 테스트 데이터셋을 정의했으니 이미지를 생성해주자
# 학습 데이터셋 생성
train_images = train_generator.flow_from_dataframe(
dataframe = train_df,
x_col = "Filepath",
y_col = "Label",
target_size = (224,224), # MobileNetV2 모델에 맞게 조정
color_mode = 'rgb',
class_mode = 'categorical',
batch_size = 32,
shuffle = True,
seed = 0,
rotation_range = 30,
zoom_range = 0.15,
width_shift_range = 0.2,
height_shift_range = 0.2,
shear_range = 0.15,
horizontal_flip = True,
fill_mode = 'nearest') # 이미지 변환 후 --
# 평가 데이터셋 생성
val_images = train_generator.flow_from_dataframe(
dataframe = val_df,
x_col = 'Filepath',
y_col = 'Label',
target_size = (224,224),
color_mode = 'rgb',
class_mode = 'categorical',
batch_size = 32,
shuffle=True,
seed = 0,
rotation_range = 30,
zoom_range = 0.15,
width_shift_range = .2,
height_shift_range = .2,
shear_range = 0.15,
horizontal_flip = True,
fill_mode = 'nearest')
# 테스트 이미지셋 생성
test_images = test_generator.flow_from_dataframe(
dataframe = test_df,
x_col = 'Filepath',
y_col = 'Label',
target_size = (224,224),
color_mode = 'rgb',
class_mode = 'categorical',
batch_size = 32,
shuffle=False) # 테스트 이미지셋은 그대로 예측해도 되기 때문에 섞지 안아도 됨Found 2780 validated image filenames belonging to 36 classes.
Found 334 validated image filenames belonging to 36 classes.
Found 334 validated image filenames belonging to 36 classes.
5. Load pretraind model
이미지 데이터셋 증강했으니, 데이터는 준비 끝. 이번에 사용할 모델은 MobileNetV2 모델이다. 가져오자.
# Load the pretrained model
pretrained_model = tf.keras.applications.MobileNetV2(
input_shape=(224,224,3),
include_top = False,
weights = 'imagenet',
pooling='avg'
)
pretrained_model.trainable = False
input_shape : (224,224,3)은 각각 이미지 높이, 너비, 채널을 의미한다. 컴퓨터비전에서 흔히 사용되는 표준 이미지 크기 중 하나다. MobileNetv2는 특정 입력 크기에 최적화 되어 있는데, 224x224가 그런 경우다.
include_top : 모델의 최상위층(일반적으로 분류를 위한 층)을 포함하지 않겠다는 것이다. 맞춤형 모델을 만들 때 False로 지정한다.
weights : 모델이 ImageNet 데이터셋으로 사전 훈련된 가중치를 사용하도록 설정한다.
pooling : 모델의 마지막에 평균 풀링 층을 추가한다. 모델의 출력을 단일 벡터로 압축하는 데 도움이 된다.
pretrained_model.trainable : 모델의 가중치가 훈련 중에 업데이트되지 않도록 설정한다. 사전 훈련된 가중치를 그대로 유지하면서 새로운 데이터에 모델을 그대로 적용하고자 할 때 False로 지정한다.
6. Training
모델 훈련을 실시한다.
# 사전 훈련된 모델을 새로운 모델로 구축할 때 입력 레이어로 사용한다.
inputs = pretrained_model.input
# 전이 학습을 위해서 사전 모델의 output을 입력으로 둔다.
x = tf.keras.layers.Dense(128, activation='relu')(pretrained_model.output)
x = tf.keras.layers.Dense(128, activation='relu')(x)
outputs = tf.keras.layers.Dense(36, activation='softmax')(x)
# model defenition
model = tf.keras.Model(inputs=inputs, outputs=outputs)
# compile
model.compile(
optimizer = 'adam',
loss = 'categorical_crossentropy',
metrics = ['accuracy']
)
# fitting
history = model.fit(
train_images,
validation_data = val_images,
batch_size = 32,
epochs = 5,
callbacks = [
tf.keras.callbacks.EarlyStopping(
monitor = 'val_loss',
patience = 2,
restor_best_weights=True)
]
)Epoch 1/5
87/87 [==============================] - 108s 1s/step - loss: 1.7679 - accuracy: 0.5288 - val_loss: 0.4803 - val_accuracy: 0.8952
Epoch 2/5
87/87 [==============================] - 73s 836ms/step - loss: 0.5538 - accuracy: 0.8194 - val_loss: 0.3089 - val_accuracy: 0.9042
Epoch 3/5
87/87 [==============================] - 72s 833ms/step - loss: 0.3325 - accuracy: 0.8986 - val_loss: 0.2288 - val_accuracy: 0.9341
Epoch 4/5
87/87 [==============================] - 71s 822ms/step - loss: 0.2194 - accuracy: 0.9317 - val_loss: 0.2342 - val_accuracy: 0.9311
Epoch 5/5
87/87 [==============================] - 71s 817ms/step - loss: 0.1525 - accuracy: 0.9504 - val_loss: 0.1688 - val_accuracy: 0.9581
pd.DataFrame(history.history)[['accuracy','val_accuracy']].plot()
plt.title("Accuracy")
plt.show()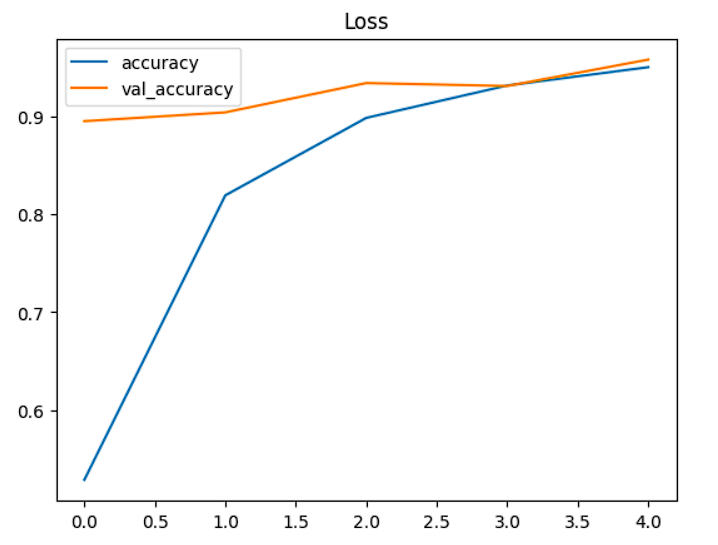
7. Evaluation
pred = model.predict(test_images)
# 어떤 요소가 가장 확률이 높았는지?
pred = np.argmax(pred, axis=1)11/11 [==============================] - 11s 955ms/step
# label class 확인
labels = (train_images.class_indices)
labels = dict((v,k) for k, v in labels.items())
pred = [labels[k] for k in pred]
y_test = [labels[k] for k in test_images.classes]
class_indices는 {'apple':0, 'banana':1, 'potato':2...} 이렇게 만드는 메소드다.
from sklearn.metrics import accuracy_score
acc = accuracy_score(y_test, pred)
print(f" Accuracy : {100 * acc:.2f}%")Acc : 95.81%
8. Visualization
혼동행렬을 시각화해서 어떤 부분에서 잘못된 예측을 했는지 알아보자.
from sklearn.metrics import confusion_matrix
import seaborn as sns
cm = confusion_matrix(y_test, pred, normalize='true')
plt.figure(figsize=(15,10))
sns.heatmap(
cm,
annotTrue,
xticklabels=sorted(set(y_test)),
yticklabels=sorted(set(y_test))
)
plt.show()
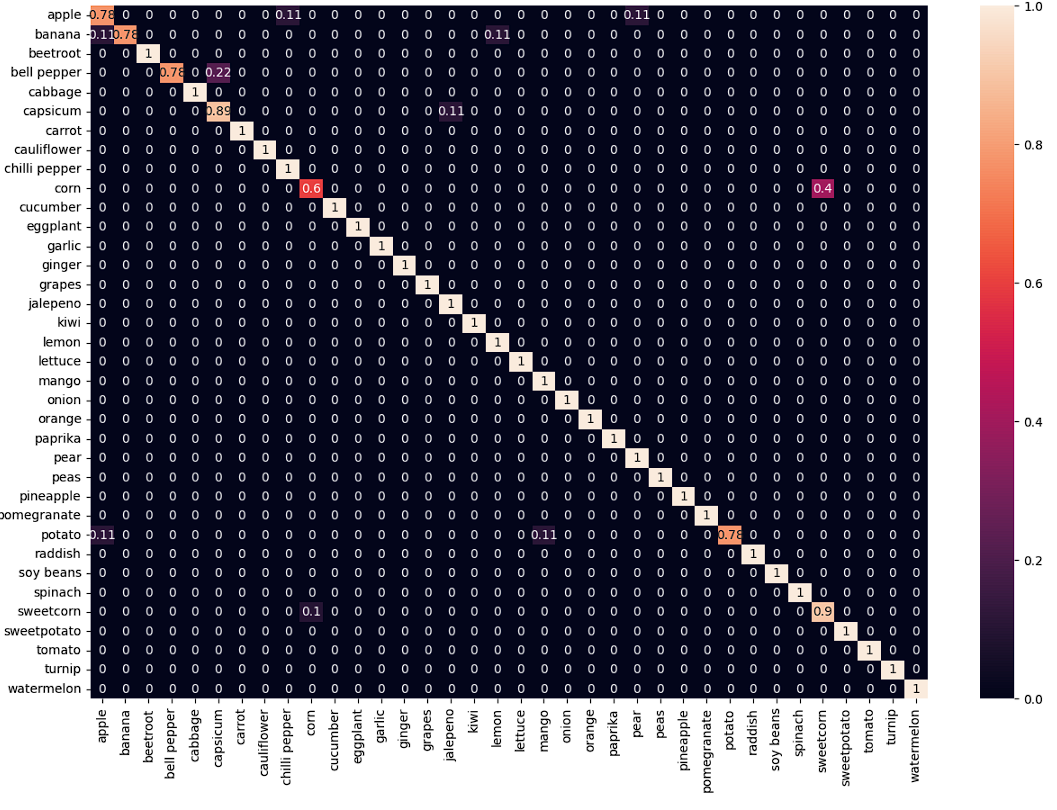
x축은 예측값, y축은 실제값이다. apple x apple 의 경우 0.78인데, '100개 중 78개 정도 정확하게 맞췄다'로 해석한다.
corn x sweetcorn이 0.4인데, 실제로는 corn인데, sweetcorn이라고 예측한 게 100개 중 40개다. 로 해석한다.
실제로 이미지로 보자.
f, axes = plt.subplots(,3,3, figsize=(15,15))
for i, ax in enumerate(axes.flat):
ax.imshow(plt.imread(test_df.Filepath.iloc[i]))
ax.set_title(f"True : {test_df.Label.iloc[i]} \n Predicted : {pred[i]}")
plt.tight_layout()
plt.show()
9. Class Activation Heatmap for image Classification
Grad-CAM class activation Visualization
Grad-CAM은 이미지 분류 작업에서 신경망이 클래스를 분류하기 위해 이미지의 어느 영역에 주목했는지 시각화하는 기술이다. 즉, 모델이 특정 클래스를 예측할 때, 중요하다고 생각하는 이미지 영역을 시각화해서 보여준다. 어떤 이미지 영역을 보고 분류했는지 사각화할 수 있으니, 이미지 내 특징을 올바르게 파악하고 예측을 했는지 확인할 수 있다.
아래 코드는 keras.io에 기술되어 있어 그대로 붙혀넣어 사용한다.
# keras.io 에서 가져옴
import matplotlib.cm as cm
def get_img_array(img_path, size):
img = tf.keras.preprocessing.image.load_img(img_path, target_size=size)
array = tf.keras.preprocessing.image.img_to_array(img)
# We add a dimension to transform our array into a "batch"
# of size "size"
array = np.expand_dims(array, axis=0)
return array
def make_gradcam_heatmap(img_array, model, last_conv_layer_name, pred_index=None):
# First, we create a model that maps the input image to the activations
# of the last conv layer as well as the output predictions
grad_model = tf.keras.models.Model(
[model.inputs], [model.get_layer(last_conv_layer_name).output, model.output]
)
# Then, we compute the gradient of the top predicted class for our input image
# with respect to the activations of the last conv layer
with tf.GradientTape() as tape:
last_conv_layer_output, preds = grad_model(img_array)
if pred_index is None:
pred_index = tf.argmax(preds[0])
class_channel = preds[:, pred_index]
# This is the gradient of the output neuron (top predicted or chosen)
# with regard to the output feature map of the last conv layer
grads = tape.gradient(class_channel, last_conv_layer_output)
# This is a vector where each entry is the mean intensity of the gradient
# over a specific feature map channel
pooled_grads = tf.reduce_mean(grads, axis=(0, 1, 2))
# We multiply each channel in the feature map array
# by "how important this channel is" with regard to the top predicted class
# then sum all the channels to obtain the heatmap class activation
last_conv_layer_output = last_conv_layer_output[0]
heatmap = last_conv_layer_output @ pooled_grads[..., tf.newaxis]
heatmap = tf.squeeze(heatmap)
# For visualization purpose, we will also normalize the heatmap between 0 & 1
heatmap = tf.maximum(heatmap, 0) / tf.math.reduce_max(heatmap)
return heatmap.numpy()
def save_and_display_gradcam(img_path, heatmap, cam_path="cam.jpg", alpha=0.4):
# Load the original image
img = tf.keras.preprocessing.image.load_img(img_path)
img = tf.keras.preprocessing.image.img_to_array(img)
# Rescale heatmap to a range 0-255
heatmap = np.uint8(255 * heatmap)
# Use jet colormap to colorize heatmap
jet = cm.get_cmap("jet")
# Use RGB values of the colormap
jet_colors = jet(np.arange(256))[:, :3]
jet_heatmap = jet_colors[heatmap]
# Create an image with RGB colorized heatmap
jet_heatmap = tf.keras.preprocessing.image.array_to_img(jet_heatmap)
jet_heatmap = jet_heatmap.resize((img.shape[1], img.shape[0]))
jet_heatmap = tf.keras.preprocessing.image.img_to_array(jet_heatmap)
# Superimpose the heatmap on original image
superimposed_img = jet_heatmap * alpha + img
superimposed_img = tf.keras.preprocessing.image.array_to_img(superimposed_img)
# Save the superimposed image
superimposed_img.save(cam_path)
# Display Grad CAM
# display(Image(cam_path))
return cam_path
preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input
decode_predictions = tf.keras.applications.mobilenet_v2.decode_predictions
last_conv_layer_name = "Conv_1"
img_size = (224,224)
# Remove last layer's softmax
model.layers[-1].ativation = None# Display the part of the pictures used by the neural network to classify the pictures
fig, axes = plt.subplots(nrows=3, ncols=3, figsize=(15, 15),
subplot_kw={'xticks': [], 'yticks': []})
for i, ax in enumerate(axes.flat):
img_path = test_df.Filepath.iloc[i]
img_array = preprocess_input(get_img_array(img_path, size=img_size))
heatmap = make_gradcam_heatmap(img_array, model, last_conv_layer_name)
cam_path = save_and_display_gradcam(img_path, heatmap)
ax.imshow(plt.imread(cam_path))
ax.set_title(f"True: {test_df.Label.iloc[i]}\nPredicted: {pred[i]}")
plt.tight_layout()
plt.show()
바나나의 경우, 배경을 제외한 모든 부분이 분류에 가장 큰 영향을 미쳤다. 망고도 그러하다. 9번째 그림 생강(ginger)은 중간 빨간 부분이 있는데 이 부분이 생강으로 분류하기에 가장 큰 영향을 미쳤다고 한다.
결론
우리는 MobileNetV2 모델을 사용해 커스터마이징을 했다. 전이 학습을 수행했다. 정확도 기준 성능이 좋다. 그리고 혼동행렬로 어떤 클래스가 어떻게 예측되고 있는지 확인했다. 또한, Grad-CAM으로 신경망 모델이 특정 클래스로 분류할 때 이미지의 어느 영역에 주목했는지 확인까지 했다. 이러한 방법으로 다른 태스크에도 적용해보면 되겠다.
'DL > Computer Vision' 카테고리의 다른 글
| Computer Vision - [얼굴 인식 2 (Face Recogintion using dlib, shape predictor 68 face landmarks)] (0) | 2024.02.07 |
|---|---|
| Computer Vision - [얼굴 인식 (Face Recogintion)] (1) | 2024.02.01 |
| Computer Vision - [CNN (Convolutional Neural Network)] (1) | 2024.01.26 |
| Computer Vision - [HOG (Histogram of Oriented Gradient)] (0) | 2024.01.26 |
| Computer Vision - [하르 캐스케이드 얼굴 탐지 (Haar Cascade Face Detection)] (1) | 2024.01.25 |