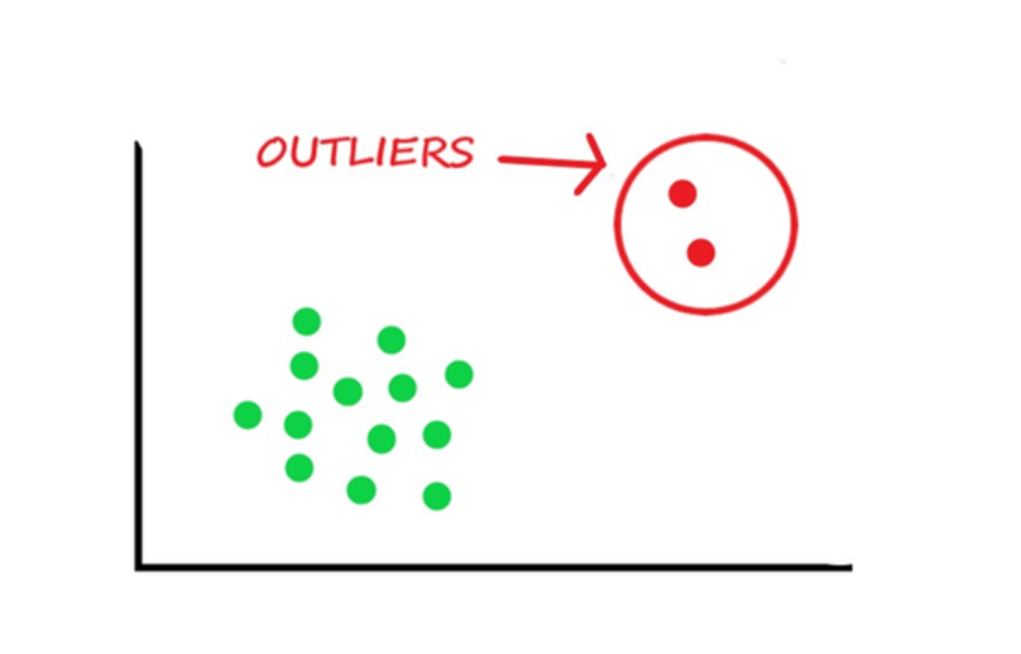
Outlier을 제거하는 것은 모델의 Performance 상승에 기여한다고 알고 있다. 하지만, 이 이상치를 제거하는 것이 꼭 타당한 방법일까? Outlier Detection 방법 중 하나인 Z-score에 대해 알아보자. 그 전에, Outlier을 제거하면 어떤 장점이 있을까? 1. Improve Model Performance : Training Dataset, Valid Dataset의 Performance가 상승하는 것을 볼 수 있다. 그러나, 경험상, Test set에서는 항상 상승하는 것은 아니다. 2. Enhance Robustness : 극값으로 인해, 평균과 분산이 흔들리게 되는데 이 극값, 즉 이상치를 제거함으로써 새로운 데이터셋에 극값이 있어도 쉽게 흔들리지 않는다. (Robust..