얼굴 인식 (Face Recogintion)
이미지에서 얼굴을 인식하고자 한다. 우선, 얼굴 탐지와 얼굴 인식의 차이를 알아야 한다.

- 얼굴 탐지 : 이미지나 영상에서 인간의 얼굴을 찾고 위치를 식별하는 것
(얼굴 인식, 감정 분석, 성별 및 연령 추정 등에서 활용됨)
- 얼굴 인식 : 얼굴이 특정 인물인지 식별하는 것이며, 얼굴을 분석하여 개인의 정체성을 확인함
(보안 시스템, 모바일 잠금 해제, 범죄자 식별 등에서 활용됨)
LBPH(Local Binary Patterns Historgram)
얼굴 인식에 사용되는 LBPH 알고리즘을 알아보자. Local Binary Pattern Histogram이다. 텍스쳐 분석에 기반을 두고, 특히 변화하는 조명 (예를 들어, 옆에서 주는 조명, 아래에서 주는 조명 등) 조건 하에서도 나쁘지 않은 성능을 보인다.
LBP

LBPH에서 LBP는 이미지의 텍스쳐를 분석하는 데 사용되는 방법이다. 각 픽셀에 대해, 그 픽셀을 중심으로 하는 작은 이웃(3x3 pixels)을 살펴보고, 중심 픽셀의 강도가 주변 픽셀의 강도보다 높거나 낮은지에 따라 이진 패턴을 생성한다. 위의 그림에서 Threshold를 90으로 주었고, Threshold보다 낮은 주변값은 0, 위의 값은 1로 주었다. 다음은 10001101로 적혀있는데 휴대폰 다이얼 순이다. 이후 십진수로 표현한다. 결과는 아래의 그림과 같이 텍스쳐로 표현된다.
* 시계 방향으로 읽어도 최종 결과에는 변함이 없어서 어떤 방식으로 이진 값 순서를 매겨도 된다. 단, 순서는 모든 픽셀에 동일하게 적용되어야 한다.

LBPH
이제, 히스토그램을 추가하면 LBPH가 된다.
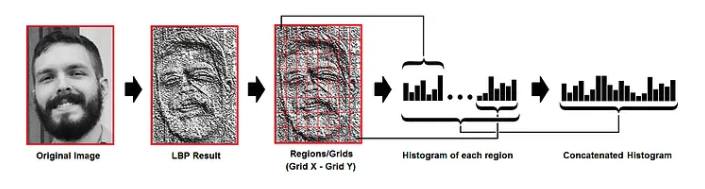
LBP Result에서 Grid X, Grid Y로 분할한다. 디폴트는 8 x 8이며, 모델 사용 전에 파라미터로 정의할 수 있다. 이렇게 되면 LBP Result에 64개의 영역이 구분된다. 각 영역에 히스토그램을 추출하고 64개의 히스토그램을 모두 결합한다. 이 히스토그램이 특정 인물의 고유 히스토그램이된다. 유클리디언 거리, 코사인 유사도와 등의 방법으로 특정인의 히스토그램을 비교한다.
여기까지가 LBPH의 간단한 설명이다. 모델을 구축해보고, 어떤 파라미터들이 있는지 살펴보자.
1. 라이브러리 가져오기
import cv2
import dlib
from google.colab.patches import cv2_imshow
from google.colab import drive
drive.mount("/content/drive")
from PIL import Image
import numpy as np
2. 데이터 가져오기
우리가 사용할 데이터셋은 예일대학교에서 제공하는 얼굴 이미지 데이터셋이다. 데이터셋은 아래에서 다운!
https://www.kaggle.com/datasets/juniorbueno/opencv-facial-recognition-lbph
OpenCV - Facial Recognition - LBPH
OpenCV - Computer Vision
www.kaggle.com
zipfile을 풀어야한다. 직접 풀어서 사용하면 되지만, 코드로 풀어보자.
import zipfile
path = "~/yalefaces.zip"
zip_object = zipfile.ZipFile(file=path, mode='r') #read mode
zip_object.extractall("./") # unzip in point work directory
zip_object.close()

3. 데이터 전처리
이미지를 바로 처리할 순 없으니 array로 바꿔줘야한다.
import os
def get_image_data():
# train 폴더에 있는 파일들을 절대경로로 리스트화
paths = [os.path.join("~/train", f) for f in os.listdir("~/train")]
# 개인의 얼굴, ID 리스트 생성
faces = []
ids = []
# 각 파일별로 gray scale로 변환 후, 배열로 변환
for path in paths:
image = Image.open(path).convert("L") # L은 Luminance, 휘도를 뜻하며 gray scale로 바꿈
image_np = np.array(image, 'uint8')
# os.path.split로 최하위 폴더와 파일을 구분
# 즉 [~/train, subject1_sad.gif]로 구분됨
# subject1_sad.gif를 .을 기준으로 구분하고 subject1 -> 1로 변환
id = int(os.path.split(path)[1].split(".")[0].replace("subject", ""))
ids.append(id)
faces.append(image_np)
return np.array(ids), faces
ids, faces = get_image_data()
len(ids), len(faces)(135, 135)
4. LBPH 알고리즘 사용
전처리까지 했으니 LBPH 알고리즘을 사용해보자. 사전에 파라미터를 정의해줄 수 있다.
lbph_classifier = cv2.face.LBPHFaceRecognizer_create(radius=4, neighbors=14, grid_x=9, grid=9)
lbph_classifier.train(faces, ids) # Image array, id array
lbph_classifier.write("lbph_classifier.yml")
radius는 반경을 의미하며, neighbors는 이웃할 픽셀의 수, grid_x,y는 그리드 수를 정의한다.
5. 얼굴 인식
다시 가져와서, 실제로 테스트 이미지로 실험해보자.
# 다시 가져오자
lbph_face_classifier = cv2.face.LBPHFaceRecognizer_create()
lbph_face_classifier.read("/content/lbph_classifier.yml")
test_image = "/content/yalefaces/test/subject05.sleepy.gif"
image = Image.open(test_image).convert("L")
image_np = np.array(image, "uint8")
image_nparray([[119, 129, 130, ..., 255, 255, 255],
[252, 255, 255, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255],
...,
[255, 255, 255, ..., 91, 89, 93],
[255, 255, 255, ..., 102, 97, 102],
[ 68, 68, 68, ..., 68, 68, 68]], dtype=uint8)
테스트 이미지 예측
prediction = lbph_face_classifier.predict(image_np)
prediction(5, 43.49027176386865)
이 이미지는 id를 5번으로 예측했고, 약 43.49정도의 신뢰도를 가진다. 실제로 5번 코드에 test_image의 경로는 subject05라, 정확하게 맞췄다.
이미지로 나타내기
실제값과 예측값을 이미지에 표현해보자.
# 실제값
expected_output = int(os.path.split(test_image)[1].split(".")[0].replace("subject", ""))
cv2.putText(image_np, "Pred :" + str(prediction[0]), (10, 30), cv2.FONT_HERSEY_COMPLEX_SMALL, 1, (0,255,0))
cv2.putText(image_np, "Exp :" + str(expected_output), (10, 50), cv2.FONT_HERSEY_COMPLEX_SMALL, 1, (0,255,0))
cv2_imshow(image_np)
6. 평가
그러면, 이 모든 이미지에 이렇게 처리를 하고 평가지표를 사용해서 평가를 해보자.
paths = [os.path.join("~/test", f) for f in os.listdir("~/test")]
predictions = []
expected_outputs = []
for path in paths:
image = Image.open(path).convert("L")
image_np = np.array(image, "uint8")
prediction, _ = lbph_face_classifier.predict(image_np)
expected_output = int(os.path.split(path)[1].split(".")[0].replace("subject", ""))
predictions.append(prediction)
expected_outputs.append(expected_output)
predictions = np.array(predictions)
expected_outputs = np.array(expected_outputs)from sklearn.metrics import accuracy_score, confusion_matrix
accuracy_score(expected_outputs, predictions)0.7지금은 0.7인데, 파라미터를 사전에 정의할 때 디폴트값으로만 하면 0.6정도가 나온다. 파라미터를 조정하면서 정확도를 최대한 끌어올리면 된다. 하지만, 70%의 정확도면 AI에 맡기지 않고 직접 사람이 구분하는게 더 정확도가 높을 것이다.
혼동 행렬
어느 레이블이 잘 분류되었고 잘못 분류되었는지 확인해보자.
cm = confusion_matrix(expected_outputs, predictions)
# 해석시, 왼쪽은 exp이고 index로 표현된거임 (subject01 -> 0)
import seaborn as sns
sns.heatmap(cm, annot=True, square=True);
Insight
y축 레이블은 실제값이고 x축 레이블은 예측값이다. 실제값이 0인데 0으로 예측한 건 1개, 3으로 예측한 것이 1개가 있다는 의미다. 또한 실제값 1은 3과 11로 예측했다. index로 표현되었기 때문에, +1 을 해줘야한다. 즉, 실제값이 0인데 0으로 예측한 건 1개, 3으로 예측한 것이 1개가 있다는 건, ID가 1인 사람은 1과 4의 ID로 각각 예측했다는 의미! 컴퓨터 성능과 가중치 무작위 초기화로 인해 다른 결과가 나올 수 있다.
'DL > Computer Vision' 카테고리의 다른 글
| Computer Vision - [CNN with tensorflow] (0) | 2024.02.20 |
|---|---|
| Computer Vision - [얼굴 인식 2 (Face Recogintion using dlib, shape predictor 68 face landmarks)] (0) | 2024.02.07 |
| Computer Vision - [Fruit and Vegetable Classification] (1) | 2024.01.29 |
| Computer Vision - [CNN (Convolutional Neural Network)] (1) | 2024.01.26 |
| Computer Vision - [HOG (Histogram of Oriented Gradient)] (0) | 2024.01.26 |