Spark

#spark
from pyspark.sql import SparkSession
saprk = Saprk.Session.builder.appName("").getOrCreate()
#inferSchema = True를 하면 자동으로 자료형을 유추해준다.
df = spark.read.csv("apple_stock.csv", header = True, inferSchema = True)
df.show()
df.printSchema()1. Select columns
변수를 지정하여 출력할 수 있다.

df.select(["age","name"])2. New columns
새 변수를 생성할 수 있고 이름을 변경할 수 있다.
아래 [그림 3]은 'newage' 변수를 생성한 결과이다.

df.withColumn('newage', df['age']).show()이제 'newage' 값들을 2배하여 'double_age'로 바꾸어보자.

df.withColumn('double_age', df['age'] * 2).show()3. Replace
변수명을 바꿀 수 있다.
withColumn과 withColumnRenamed의 매개변수 순서가 다른 것을 주의하자!
위에서 withColumn을 사용했을 땐, 새로운 변수명, 기존 변수명으로 매개변수를 두었지만, withColumnRenamed를 사용할 때는 기존 변수명, 새로운 변수명 순으로 지정해야한다는 것이다.

df.withColumnRenamed('age','my_new_age').show()4. filtering
R, SQL과 유사하게 필터링을 할 수 있다.
아래 [그림 6]은 Apple Stock의 시초가가 200$이상이고 종가가 200$ 미만으로 하락한 일자를 가져오고 시초가 컬럼만 확인한 결과이다.

df.filter( (df["Close"] < 200) & (df["Open"]) > 200) ).select(['Open']).show()5. Collect
출력된 결과에서 추가적으로 작업할 수 있다.
즉, .show()로 출력된 결과를 확인했는데 그 출력된 결과에서 어떤 작업을 해볼 수 있다.
아래 [그림 7]과 [그림 8]은 Apple Stock이 197.16일 때의 거래량을 확인한 결과이다.

results = df.filter(df["Low"] == 197.16).collect()
results여기서 인덱싱을 사용하여 거래량(Volume)을 확인해보자.

results[0]["Volume"]위 [그림 7]의 경우 list형식으로 출력되었는데, asDict()를 활용하여 dictionary형식으로도 바꿀 수 있다.
여기서부터 다른 데이터를 활용한다. 회사에서 어떤 종사자가 많이 판매하였는지에 대한 데이터이다.
데이터는 아래 [그림 9]와 같다.
from pyspark.sql import SparkSession
spark= SparkSession.builder.appName("aggs").getOrCreate()
df = spark.read.csv("../sales_info-1.csv", header=True, inferSchema=True)
6. Groupby
그룹별로 확인할 수 있다. (mean, sum, min, max, count...)

df.groupBy("company").mean().show()7. Aggregate
컬럼을 기준으로 연산을 할 수 있다.
아래 [그림 11]은 전체 판매량을 출력한 결과이다.

df.agg[{'sales':"sum"}].show()groupby와 aggregate를 같이 사용할 수 있다.

#회사별
group_data = df.groupBy("company")
#회사별 최대매출
group_data.agg({"sales":"max"}).show()8. function
함수를 쓰고 싶을 때는 라이브러리를 불러와야한다.
아래 [그림 13]은 판매량의 평균을 출력한 결과이다.
from pyspark.sql.function import countDistinct, avg, stddev, mean
df.select(avg("sales")).show()
위 [그림 13]에서 출력된 컬럼명을 변경할 수 있다. alias를 사용한다.

sales_std = df.select(stddev("sales").alias("stddev_samp(sales)"))
sales_std.show()소수점 2자리로 표현해보자.

#format_number 함수를 쓰기위해 라이브러리 가져오기
from pyspark.sql.function import format_number
sales_std.select(format_number('stddev_sampe(sales)',2).alias("Final")).show()9. Orderby
데이터를 정렬할 수 있다.
아래 [그림 16]은 데이터를 오름차순으로 정렬한 결과이다.

df.orderBy(df["Sales"]).show() #increasing
#df.orderBy(df["Sales"].desc()).show() #descending10. Null
Null 데이터를 처리할 수 있다.
아래 [그림 17]은 새로운 데이터를 가져온 출력 결과이다.

df = spark.read.csv("../~.csv",inferSchema = True)
df.show()아래와 같은 코드로 결측치를 다룰 수 있다.
df.na.drop() #하나라도 결측치가 있다면 drop을 한다.
df.na.drop(thresh=2).show() #threshold
df.na.drop(how='all').show()
df.na.drop(subset=['Sales']).show()e.g. 결측치를 0으로 채워보자.
똑똑하게도 0으로 채우려 하면 Numeric 변수에만 처리해준다.
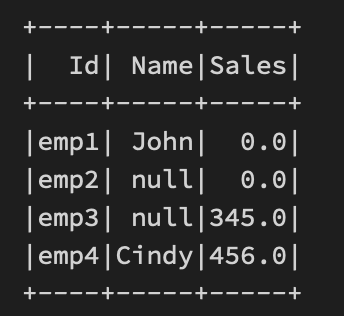
df.na.fill(0).show()
Name에 있는 Null을 처리해보자.

df.na.fill("Fill Values").show()> 헷갈리니까 Subset으로 column을 지정해주자.

df.na.fill("No Name", subset=['Name']).show()11. Date
Datetime을 처리할 수 있다.
데이터는 애플 주식 가격 데이터로 진행한다.

from pyspark.sql.functions import to_date, col
df = df.withColumn("Date",to_date(col("Date"), "yyyy-MM-dd"))
df.select(["Date", "Open"]).show()Date 컬럼에서 일(day)을 추출해보자.

from pyspark.sql.functions import (dayofmonth, hour, dayofyear, format_number,
date_format, year, weekofyear)
df.select(dayofmonth(df["Date"]).show()예제) 매 년 평균 종가는 어떻게 되는가?
1.

df.withColumn("Year", year(df["Date"])).show()
newdf = df.withColumn("Year", year(df["Date"]))
newdf.groupBy("Year").mean().show()
result = newdf.groupBy("Year").mean().select(["Year","avg(Close)"])
result.show()마지막으로 변수명을 바꾸어주고 소수점 둘째 자리까지만 표현해보자.

new = newdf.withColumnRenamed("avg(Close)","Average Closing Price")
new.select(["Year", format_number("Average Closing Price",2).alias("Average)]).show()
'Spark' 카테고리의 다른 글
| Spark - [Clustering] (0) | 2022.12.12 |
|---|---|
| Spark - [Tree Model] (0) | 2022.12.12 |
| Spark - [Logistic Regression] (0) | 2022.12.11 |
| Spark - [Regression Analysis] (2) | 2022.12.11 |
| Spark - [pyspark] (0) | 2022.12.08 |