Tree Model
먼저, spark 환경을 구축하자. 이젠 익숙할 것이다.
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Tree").getOrCreate()
data = spark.sql("SELECT * FROM college_csv")이번 데이터는 아래 [그림 1]처럼 구성되어 있다.
Private 변수를 이진 분류하는 Task이다.

df.printSchema()VectorAssembler
독립변수들을 묶어준다.
VectorAssembler로 독립변수들을 묶어주자.
from pyspark.ml.feature import VectorAssembler
#Inputcols, Outputcols
assembler = VectorAssembler(inputCols = ['Apps','Accept','Enroll','Top10perc',
'Top25perc','F_Undergrad','P_Undergrad','Outstate',
'Room_Board','Books','Personal', 'PhD','Terminal',
'S_F_Ratio','perc_alumni','Expend','Grad_Rate'], outputCol='features')묶어주었으니 데이터 변형해주자.
마지막 컬럼에 'features : vector'가 보인다.

output = assembler.transform(data)
output
StringIndexer
0과 1로 바꾸어준다.
'Private'가 Target인데 본 데이터에는 Yes, No로 String으로 되어있다. 0과 1로 StringIndexer을 사용해서 바꾸어주자.
(OnehotEncoding이랑 헷갈리면 안된다.)아래 [그림 3]은 출력 결과이다.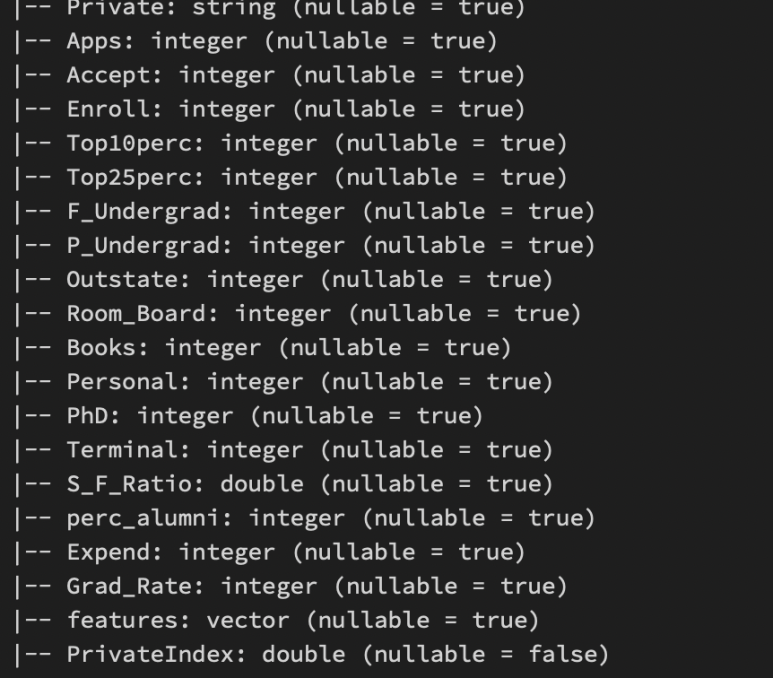
from pyspark.ml.feature import StringIndexer
indexer = StringIndexer(inputCol = "Private", outputCol = "PrivateIndex")
#fit_transform
output_fixed = indexer.fit(output).transform(output)
output_fixed.printSchema()최종적으로 사용할 변수는 아래와 같다.
final_data = output_fixed.select("features","PrivateIndex")Train Test Split
train_data, test_data = final_data.randomSplit([.7, .3])Modeling
Tree 기반의 모델을 구축해보자.
불편하게도 .predict()를 쓰지 않고 .transform()을 쓴다.
from pyspark.ml.classification import (DecisionTreeClassifier, GBTClassifier,
RandomForestClassifier)
from pyspark.ml import Pipeline
#Modeling
#parameter 조정도 가능하다.
dtc = DecisionTreeClassifier(labelCol='PrivateIndex', featuresCol='features')
rfc = RandomForestClassifier(labelCol='PrivateIndex', featuresCol='features', maxDepth=10)
gbt = GBTClassifier(labelCol='PrivateIndex',featuresCol='features')
#fitting
dtc_model = dtc.fit(train_data)
rfc_model = rfc.fit(train_data)
gbt_model = gbt.fit(train_data)
#prediction
dtc_preds = dtc_model.transform(test_data)
rfc_preds = rfc_model.transform(test_data)
gbt_preds = gbt_model.transform(test_data)Evaluate
이진 분류 평가를 할 수 있다.


from pyspark.ml.evaluation import BinaryClassificationEvaluator
binary_eval = BinaryClassificationEvaluator(LabelCol = "PrivateIndex")
print("AUC of DTC")
print(binary_eval.evaluate(dtc_preds))
print("AUC of RFC")
print(binary_eval.evaluate(rfc_preds))
다중 분류 평가도 할 수 있다.
[그림 6] 위의 값은 정확도이고 아래는 f1-score 값이다.

from pyspark.ml.evaluation import MulticlassClassificationEvaluator
#accuracy & f1-score
acc_eval = MulticlassClassficiationEvaluator(labelCol="PrivateIndex",metricName="accuracy")
f1_eval = MulticlassClassficiationEvaluator(labelCol="PrivateIndex",metricName="f1")
print(acc_eval.evaluate(rfc_preds)) #accuracy
print(f1_eval.evaluate(rfc_preds)) #f1-score'Spark' 카테고리의 다른 글
| Spark - [Recommend System] (0) | 2022.12.13 |
|---|---|
| Spark - [Clustering] (0) | 2022.12.12 |
| Spark - [Logistic Regression] (0) | 2022.12.11 |
| Spark - [Regression Analysis] (2) | 2022.12.11 |
| Spark - Basic (0) | 2022.12.08 |