확실하지 않은 예측값
우리는 보통 미래값을 예측할 때, 통계 모형 또는 ML/DL 알고리즘을 사용한다. 그런데, 예측값을 믿을 수 있을까?
실세계에서는 다양한 변수가 존재하기 때문에, 예측값은 딱 맞아떨어지지 않는다. 예측값이 어느정도로 불확실한지 측정할 필요가 있다.
최근에, 제주 특산물 가격 예측 경진대회를 했다. 각 특산물의 한 달동안 가격을 예측했다. 그런데, 다양한 요인으로 인해 이게 딱 떨어지지 않을 것이라 판단했다. 예측값이 어느정도의 신뢰구간을 가지는지 궁금했다.
신뢰구간
불확실성을 측정할 때는 보통 '신뢰구간'을 활용한다. 미리 신뢰구간을 몇 %로 할 건지 정하면, 예측값이 포함된 신뢰구간이 어느정도인지 알 수 있다. 다음 단계 설명을 위해 '신뢰구간'에 대해 알아볼 필요가 있다.
신뢰구간은 간단하다. 어디까지 변동성을 가지는지 확인할 때 사용한다.
예를 들어 제주도 특산물인 귤의 무게를 구해보자. 어마하게 많은 귤의 무게를 전체 잴 수 있을까? 어려울 것이다. 하나씩 가져와서 몇 백 아니, 몇 천만개의 귤의 무게를 잴 것인가?
우리는 그래서 엄청 많은 귤 중에 30개만 추출해보자. 이렇게 한 번 추출하고 무게를 재본다. 30g이다. 또 30개를 추출해본다. 이전에 추출되었던 귤을 또 추출해도 상관없다. 무게를 재보니 28g이다. 이렇게 반복적으로 100번 추출하고 무게를 쟀다.
추출한 각 표본들의 평균 무게가 각각 (30g, 28g, 25g, 31g, 41g, 42g, 33g, ...) 이다. 이 때 우리는 신뢰구간을 만들 수 있다. 단, 몇 %의 신뢰구간을 만들 것인지는 미리 정해두어야 한다. 몇 %가 좋을까? 그건 연구와 시간, 비용에 따라 다르다.
신뢰구간 95%로 정했다면 아래 공식으로100개의 구간이 만들어진다.
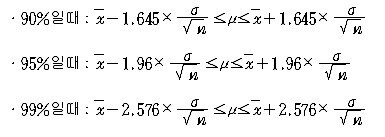
표본의 크기가 30개 이상 충분히 크기 때문에, 전체 귤 무게의 분산을 몰라도 정규분포를 사용할 수 있다. 그러면 100개의 구간이 나온다. 이 때 100개 중 5개는 모평균을 포함하지 않는 구간이 존재한다. 왜? 95% 신뢰구간이라 했으니 5%는 신뢰할 수 없는 구간이니까.
이 때 해석이 중요한데, 95% 신뢰구간을 95%의 확률로 모평균이 포함된다로 해석해선 안된다. 모평균은 이미 정해져있는 상수값이지 변하는 확률값이 아니다. 그래서 이미 모평균을 포함한! 신뢰구간이! 100개 중 95개가 있다! 로 생각해야한다.
이렇게 간단하게 신뢰구간에 대해 설명했다. 본격적으로 예측값에 대한 불확실성을 추정해보자. 우리는 이를 컨포멀 프레딕션이라고 한다. (Conformal Prediction)
EnbPI
Conformal Prediction을 위해 EnbPI 알고리즘을 만들었다.
EnbPI는 훈련 단계와 예측 단계로 구분된다.

훈련단계
먼저, 부트스트랩 모델을 몇 개를 만들건지 B를 정하고, 비복원추출로 추출한다. 보통 20~50으로 정한다.
비복원추출이기에 데이터가 작은 경우 한계점이 있기도 한다. 그리고 LOO 기법으로 잔차를 확인한다.

예측 단계
예측 단계에서 EnbPI는 각 예측 모형을 사용해서 모든 단일 테스트 데이터 포인트에 대해 예측한다. 이 예측값들은 예측 구간의 중심을 계산하기 위해 집계된다. 이후 잔차의 분위수를 사용해서 예측 구간(prediction interval) 을 구성한다. 이 구간의 너비는 프로세스에 최적화되어 특정 신뢰 수준에 대해 가능한 가장 좁은 너비를 얻는다. 또한, 예측 단계에서 새로운 값이 관찰되면 적응성을 위해 간격이 업데이트된다.
python으로 사용하고자 하면, mapie library를 설치해서 사용하면 된다.
'ML' 카테고리의 다른 글
| ML - [Model Evaluation] (0) | 2022.12.20 |
|---|