Spark
Spark - [NLP(Natual Language Processing)]
_data
2022. 12. 13. 00:28
NLP(Natual Language Processing)
자연어처리를 해보자.
우리의 목표는 메시지가 스팸인지 아닌지 구분하는 모델을 만드는 것이다.
Spark
아래 [그림 1]은 우리가 다룰 데이터이다.

from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('nlp').getOrCreate()
data = spark.sql("SELECT * FROM smsspamcollection")
data.show()변수명을 바꾸어주자.

data = data.withColumnRenamed("_c0","class").withColumnRenamed("_c1","text")feature engineering
자연어 처리 때 feature engineering을 하는 것 중 하나가 length이다.
아래 [그림 3]을 보면 ham의 문자열 길이 평균이 71글자이고 spam의 경우는 138글자이다.
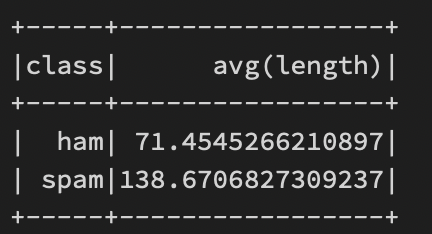
data.groupBy("class").mean().show()Preprocessing
전처리를 하자.
from pyspark.ml.feature import (Tokenizer, StopWordsRemover,CountVectorizer,IDF,StringIndexer)
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.classification import LinearSVC
from pyspark.ml import Pipeline
#text to token
tokenizer = Tokenizer(inputCol="text", outputCol="token_text")
#stopwords removing
stop_remove = StopWordRemover(inputCol="token_text",outputCol="stop_tokens")
#vectorizing
cv = CountVectorizer(inputCol="stop_tokens", outputCol="countVector")
#tf-idf
idf = IDF(input_col="countVector",outputCol="tf_idf")
#to numeric variables
ham_spam_to_numeric = StringIndexer(inputCol="class", outputCol="label")VectorAssembler & Pipeline
clean_up = VectorAssembler(inputCols=["tf_idf", "length"], outputCol="features")
#model
svc = Linear()
#pipeline
pipe = Pipeline(stages=[ham_spam_to_numeric, tokenizer, stop_remove, cv, idf, clean_up])
#fit
clean_data = pipe.fit(data).transform(data)
#finalize
clean_data = clean_data.select("label","features")
clean_data.show()Train Test Split
모든 과정을 다 했으니 데이터셋을 분리시키자.
train_data, test_data = clean_data.randomSplit([.7,.3])Modeling

spam_detector = svc.fit(train_data)
#results
test_results = spam_detector.transform(test_data)
test_resultsEvaluation
아래 [그림 5]를 보면 SVC의 정확도를 알 수 있다. 약 96% 정확도로 스팸인지 아닌지 구분해준다.

from pyspark.ml.evaluation import MulticlassClassificationEvaluator
acc_eval =MulticlassClassificationEvaluator()
acc=acc_eval.evaluate(test_results)
print("ACC of SVC")
print(acc)