Spark
Spark - [Clustering]
_data
2022. 12. 12. 23:39
Clustering

비지도 학습 중 하나인 클러스터링을 작성해보자.
시작하기 전에, 도메인 지식을 활용해서 몇 개의 군집을 나눌지 미리 정해두어야 한다.
Spark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("C").getOrCreate()
data = spark.sql("SELECT * FROM seeds_dataset.csv")불러온 데이터셋은 아래 [그림 1]과 같다.

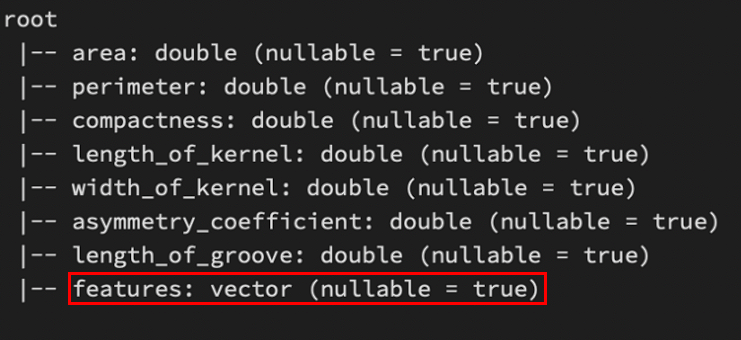
data.printSchema()VectorAssembler
사용할 독립변수를 묶어준다.
from pyspark.ml.feature import VectorAssembler
assembler = VectorAssembler(inputCols = data.columns, outputCol="features")
final_dataset = assembler.transform(data)
final_dataset.printSchema()StandardScaler
표준화 작업을 할 수 있다.
컬럼 별 단위가 다르기 때문에 해주는 것이 좋다.

from pyspark.ml.feature import StandardScaler
#withMean : mean 0, withStd : std 1
scaler = StandardScaler(inputCol="features", outputCol="Scaledfeatures",
withMean=True, withStd=True)
scaleddataset = scaler.fit(final_dataset)
scaleddataset.head(1)Clustering
from pyspark.ml.clustering import KMeans
#kmeans
kmeans = Kmeans(featureCol="Scaledfeatures", k=3, seed=42)
model = kmeans.fit(scaleddataset)
#euclidean
model.getDistanceMeasure()
#cluster median
model.clusterCenters()Prediction

model.transform(scaleddataset).select("prediction").show()